By Lina Scarborough
We’re releasing our resource, CEASR, for Speech-To-Text applications. It’s a massive collection of speech utterances that can be used with evaluation tools to help access the quality of automatic speech recognition (ASR) models.
In Brief
- Use: CEASR can be used for a range of applications, including but not limited to: a reference benchmark for ASR quality tracking; detailed error analysis (e.g. error typology by acoustic setting, development of alternative error metrics); detailed ASR quality evaluation (e.g. in relation to speaker demographic profiles or spoken language properties); and improving ASR, for example by developing ensemble learning methods based on the output of different systems.
- Benefit: CEASR enables researchers to perform ASR-related evaluations and various in-depth analyses with noticeably reduced effort: without the need to collect, transcribe, and normalize the speech data themselves.
- Findings: commercial cloud providers perform better than pre-trained open source solutions (measured by Word Error Rate, WER). Also, we observed differences up to ten-fold between the results within the same ASR system across different corpora. It is thus difficult to say there is such a thing as one absolute WER for each system because it depends so much on the speaking style.
- Read the original paper here.
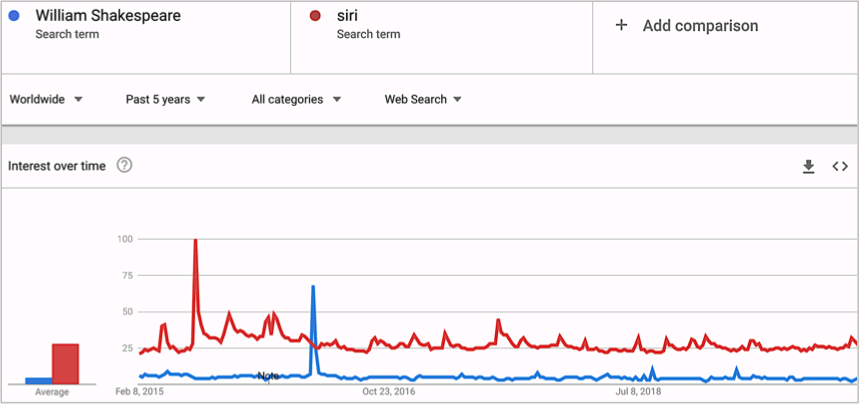
Where would we be without voice assistants and YouTube auto-captions? Imagine the horror of manually dialing a phone number on some clunky apparatus just to order food – the thought is practically Neolithic. Why bother when Siri can now order pizza for you? In fact though, all jokes and sarcasm aside, we search for Siri more than for Shakespeare (Google search-term hits peaking in mid-2015) and whilst many trends may wax and wane with time, the demand for automatic speech recognition is not one of them.
The Purpose
Seeing as a chain is only as strong as its weakest link, any ASR system is only as good as its accuracy. We set out to scrutinize precisely this using sclite, a speech recognition scoring toolkit, and CEASR as a corpus. A door to both further research in the realm of heavy-spectacled academics as well as ambitious business applications, the guys who figure out how to reduce Word Error Rates (WER) will not only get to have their cake, but eat it as well.
A tool in the judge’s hands: CEASR
Now to CEASR1, which stands for ‘Corpus for Evaluating ASR’ quality – a kingly name for a powerful resource. It’s a data set of over 56’000 utterances from 70.5 hours of audio recordings, derived from public speech corpora containing manual transcripts enriched with metadata.
The Judged: ASR Systems
Seven systems were evaluated; four of which on both English and German. These transcripts were generated by proprietary cloud services. Since we are bound by confidentiality restrictions, we can’t disclose their names. Therefore, we simply refer to them as Systems 1, 2, 3 and 6. Although the open-source systems have no such constraints, we can provide their names, but for unity of format we also used numbers to refer to them. These remaining three open-source systems were used to transcribe English corpora only: Mozilla DeepSpeech version 0.5.1, Kaldi version 5.5 and CMUSphinx sphinx4.
| Commercial ASR (EN & DE) | Open-source ASR (EN) |
|---|---|
| System 1 – Tested 9 different EN corpora- Tested 6 different DE corpora | System 4 (Kaldi) – Tested 9 different EN corpora |
| System 2 – Tested 9 different EN corpora – Tested 6 different DE corpora | System 5 (Mozilla DeepSpeech) – Tested 9 different EN corpora |
| System 3 – Tested 9 different EN corpora – Tested 6 different DE corpora | System 7 (Sphinx) – Tested 9 different EN corpora |
| System 6 – Tested 9 different EN corpora – Tested 6 different DE corpora |
The Results: Commercial Systems FTW
We used sclite, a tool for scoring and evaluating speech recognition output, to do a detailed comparison of the WER performance of different systems. We determined two valuable findings: commercial systems performed better than open source ones; and, it can be argued that there is no such thing as an ‘absolute’ WER due to differences in speaking styles of corpuses. More on this below.
The winner with the lowest error rate was the commercial system 2.
In fact, currently there is a substantial quality difference between commercial versus open-source ASR tools. We speculate this is the case because commercial systems have larger training sets available to them.
We also found that the difference between performance on various corpora within the same system is larger than between systems within the same corpus. The same systems had significantly different results on different corpora (differences in WER up to ten-fold).
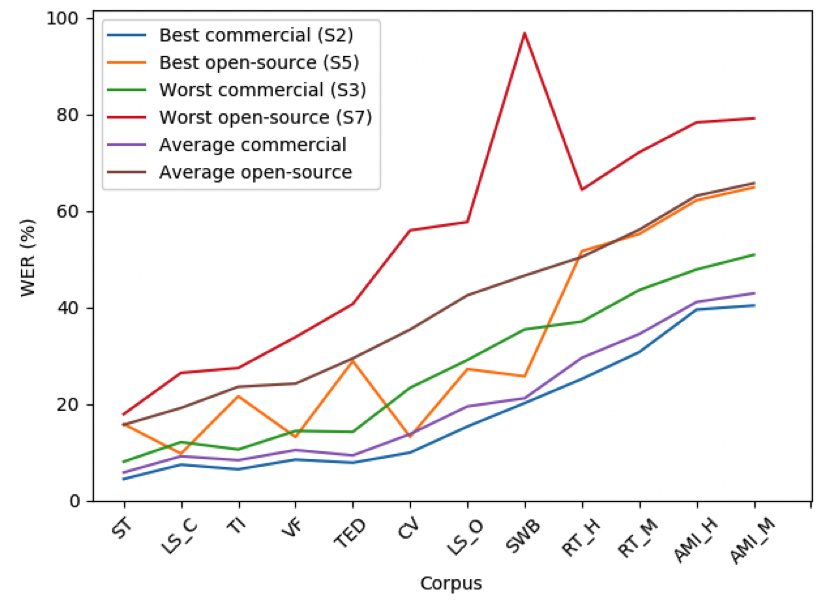

We determined that systems S2, S6 and S1 were not just the best in terms of quality, but they perform consistently well across various difficulties of speech data. Only the commercial system S3 had substantially higher WERs, particularly on spontaneous speech corpora. The worst score has been achieved on AMI Headset Mix (for all systems).
In the evaluation for German, the top two systems are the same as for English, albeit with a different ranking: S6 in the first place and S2 in the second.
The point is also that CEASR makes obtaining analysis results vastly easier, since it solves the tedious problem of collecting, normalizing and transcribing speech data.
A rose by any other name – just not within ASR systems
On the contrary, CEASR’s speech corpora includes a wide variety properties listed below, thereby allowing a nuanced evaluation of ASR performance:
- A variety of speaking styles
- Read-aloud vs. spontaneous
- Monologue vs. dialogue
- Speaker demographics
- Native vs. non-native
- Dialectal regions
- Age
- Gender
- Native language
- Recording environments
- Audio quality types
- Recording studio vs. telephone line
We ain’t talking good
This kind of goes without saying, but spontaneous speech, that is, normal, unrehearsed chatting, is much harder for software to transcribe without error. Dialogue speech is challenging due to non-canonical pronunciations, acoustic and prosodic variability, and high levels of disfluency, e.g. repetitions, false starts, repaired utterances and stuttering3. Spontaneous speech is additionally characterized by accelerated speaking rates and higher proportions of out-of-vocabulary words (OOV)4.
But that’s exactly the kind of speech that, generally, we want captured the most in interviews or discussions. What is to be done?
Well, the last of those factors looks at how machine learning (ML) can handle names or verbs that you wouldn’t find in a dictionary, like ‘Quidditch’. OOV mapping models try to predict the spelling or meaning of such words in context, namely by juxtaposing it with similar sentences.
Nice, and what’s next with CEASR?
As mentioned, our hypothesis why commercial systems are so good is that the big technology companies have much larger data sets at their disposal, resulting in better performance regardless of the speech corpora. We wonder whether using the open-source systems to train more customized models could offset this training data disadvantage. We also intend to apply CEASR for further research, such as evaluating the semantic relevance of the WER metric, as well as using the CEASR transcripts to explore ensemble methods for improving transcription accuracy.
The wrap-up in under 300 characters

CEASR is a super cool resource. It enabled us to figure out how good or bad automatic speech recognition systems are at the moment. You too can use this super cool resource in combination with evaluation tools to help access the quality of ASR models or your own STT research.
The paper was accepted by the 12th Edition of the Language Resources and Evaluation Conference (LREC) in Marseille with ID #1332 for the 2020 submissions.
Find the Corpus website here.
Keywords: automatic speech recognition, evaluation, speech corpus, ASR systems
Footnotes
- CEASR has been created from nine English speech corpora (TIMIT, VoxForge, CommonVoice, LibriSpeech, ST, RT, AMI, Switchboard, TedLium) and six German corpora (VoxForge, CommonVoice, Tuda-De, Hempel, StrangeCorpus 10, Verbmobil II v.21).
- Ulasik, M. A. et al. CEASR: A Corpus for Evaluating Automatic Speech Recognition, 2019.
- Goldwater et al., 2010, Hassan et al., 2014.
- Nakamura et al., 2008.
- Schneider, S. et al. Wav2Vec: Unsupervised Pre-Training For Speech Recognition. 2019.
- Joungbum, K., Automatic Detection of Sentence Boundaries, Disfluencies, and Conversational Fillers in Spontaneous Speech. 2004.